Time Series Optimizations
Time-series optimizations
QuestDB is specifically designed for time series, and it provides several optimizations such as a designated timestamp, sequential reads, materialized views, and in-memory processing.
Designated timestamp
-
Timestamp sorting: Data is stored in order of incremental timestamp. Since ingestion is usually chronological, the system uses a fast append-only strategy, except for updates and out-of-order data.
-
Rapid interval queries and sequential reads: Sorted data lets the system quickly locate the start and end of data files, which speeds up interval queries. When data is accessed by increasing timestamp, reads are sequential for each column file, which makes I/O very efficient.
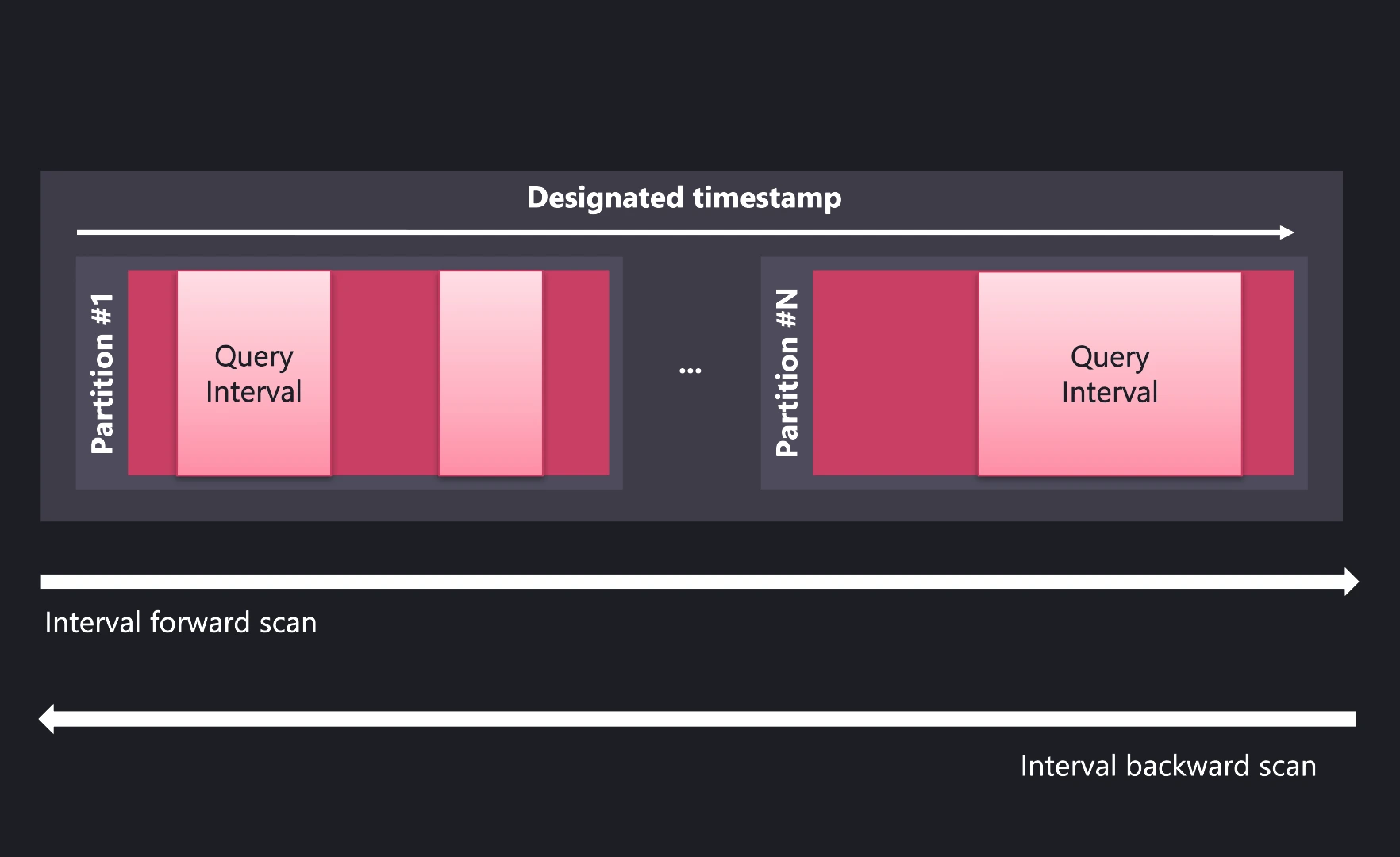
- Out-of-order data: When data arrives out of order, QuestDB rearranges it to maintain timestamp order. The engine splits partitions to minimize write amplification and compacts them in the background.
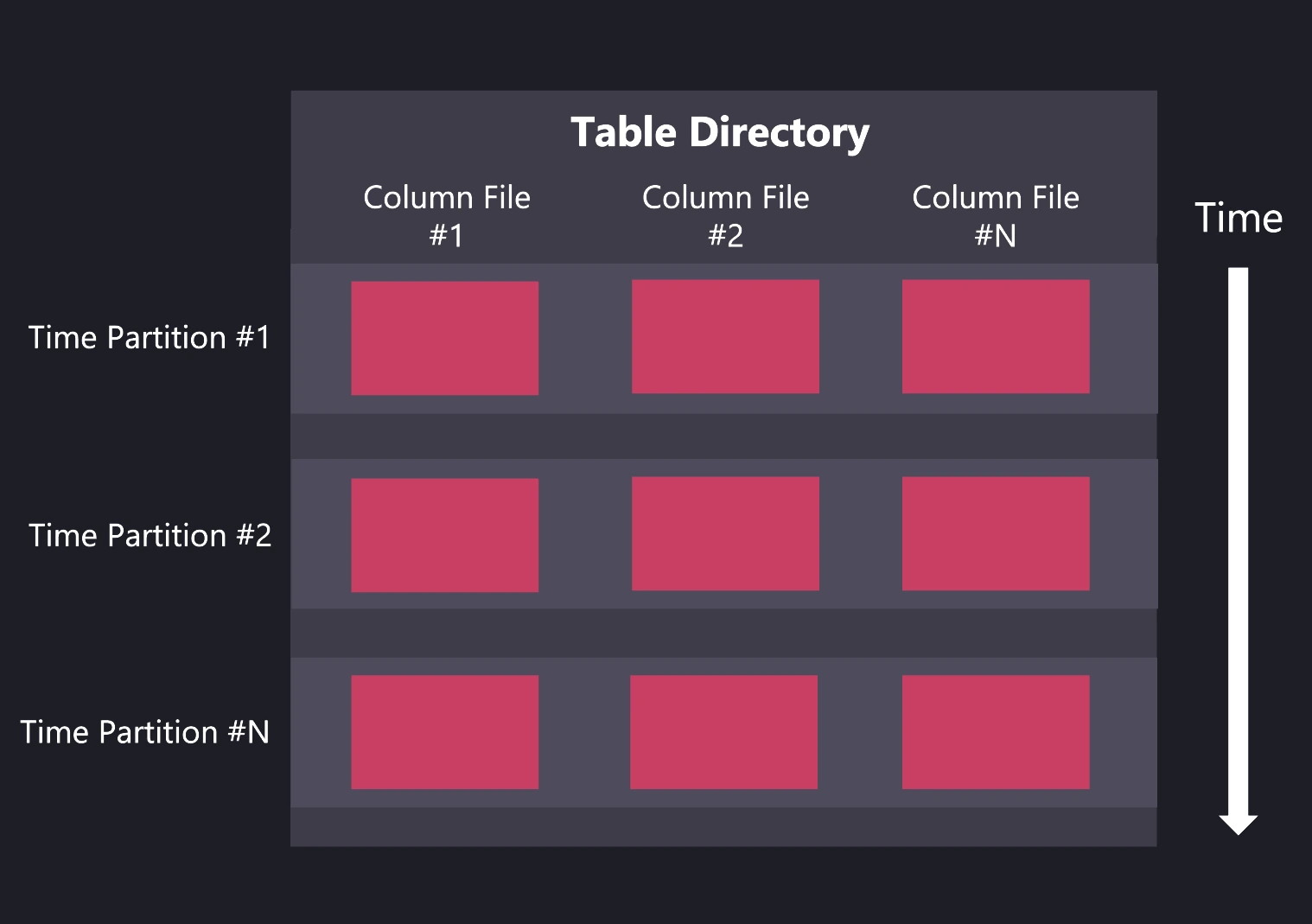
Data partitioning and sequential reads
- Partitioning by time: Data partitions by timestamp with hourly, daily, weekly, monthly, or yearly resolution.
-
Partition pruning: The design lets the engine skip partitions that fall outside query filters. Combined with incremental timestamp sorting, this reduces latency.
-
Lifecycle policies: The system can delete partitions manually or automatically via TTL. It also supports detaching or attaching partitions using SQL commands.
Materialized views
-
Materialized views are auto-refreshing tables that store the precomputed results of a query. Unlike regular views, which compute their results at query time, materialized views persist their data to disk, making them particularly efficient for expensive aggregate queries that are run frequently.
-
QuestDB supports materialized views for
SAMPLE BYqueries, including those joining with other tables. -
Materialized sampled intervals are automatically refreshed whenever the base table receives new or updated rows. QuestDB supports different strategies for self-refreshing views: Immediate, Timer, or Period (with an optional allowed delay). Views can also be configured to refresh only when manually triggered.
-
Materialized views can be chained, with the output of one serving as the input to another, and support TTLs for lifecycle management.
In-memory processing
-
Caching: The engine uses the OS cache to access recent and frequently accessed data in memory, reducing disk reads.
-
Off-heap buffers: Off-heap memory, managed via memory mapping and direct allocation, avoids garbage collection overhead.
-
Optimized in-memory handling: Apart from using CPU-level optimizations such as SIMD, QuestDB uses specialized hash tables (all of them with open addressing and linear probing) and implements algorithms for reducing the memory footprint of many operations.
-
Custom memory layout for different data types: Specialized data types such as
Symbol,VARCHAR,Array, orUUIDare designed to use minimal disk and memory. For example, character sequences shorter than 9 bytes are fully inlined within theVARCHARheader and do not occupy any additional data space.
Internal Representation of the VARCHAR data type
Varchar header (column file):
+------------+-------------------+-------------------+
| 32 bits | 48 bits | 48 bits |
| len + flags| prefix | offset |
+------------+-------------------+-------------------+
│
+------------------------------------+ points to
│
▼
Varchar data (column file):
+---+---+---+---+---+---+---+---+---+---+---+
| H | e | l | l | o | | w | o | r | l | d |
+---+---+---+---+---+---+---+---+---+---+---+
Next Steps
- Back to the QuestDB Architecture overview
- QuestDB GitHub Repository
- QuestDB Documentation